The unusualprofile package can identify multivariate outliers conditioned on a set of predictors (Ji, 2018).
Univariate Outliers
A univariate outlier is far from most of the other scores in a distribution. You can easily spot a large outlier in the histogram in Figure 1.
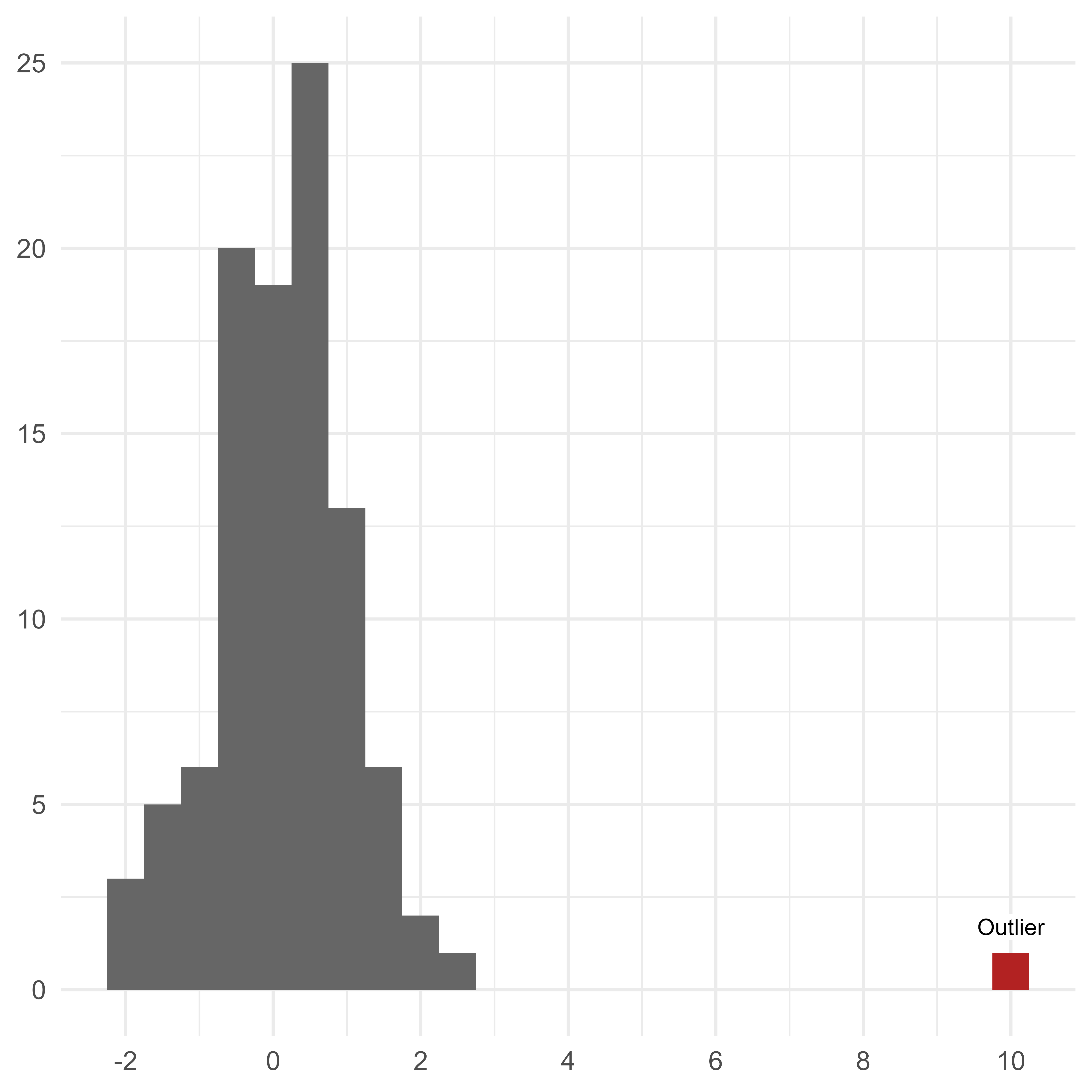
If we want to quantify the extremity of the univariate outlier, we could convert the outlier to a z-score, which indicates the outlier’s distance from the population mean in standard deviation units. In this case, the outlier is 10 standard deviations from the mean of the other scores.
Multivariate Outliers
A univariate outlier refers to a single case from a single variable. A multivariate outlier refers to a single row of data consisting of 2 or more variables.
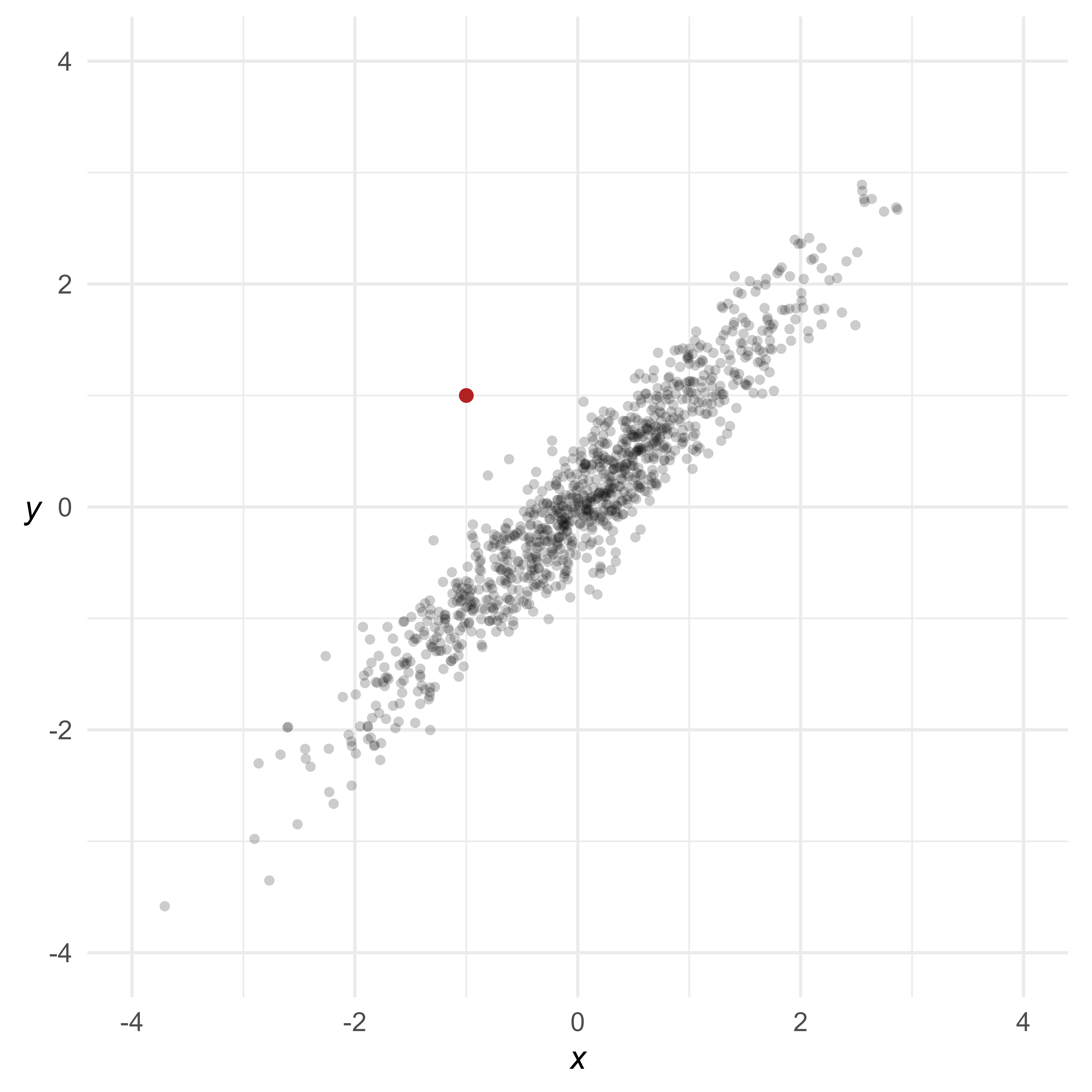
A multivariate outlier might not be unusual on any particular variable, but has an unusual pattern of scores. For example, in Figure 2, the red point is not very unusual in a univariate context—just 1 standard deviation from the mean of either variable. However, because x and y are highly correlated, it is extremely rare for a data point to differ by 2 standard deviations.
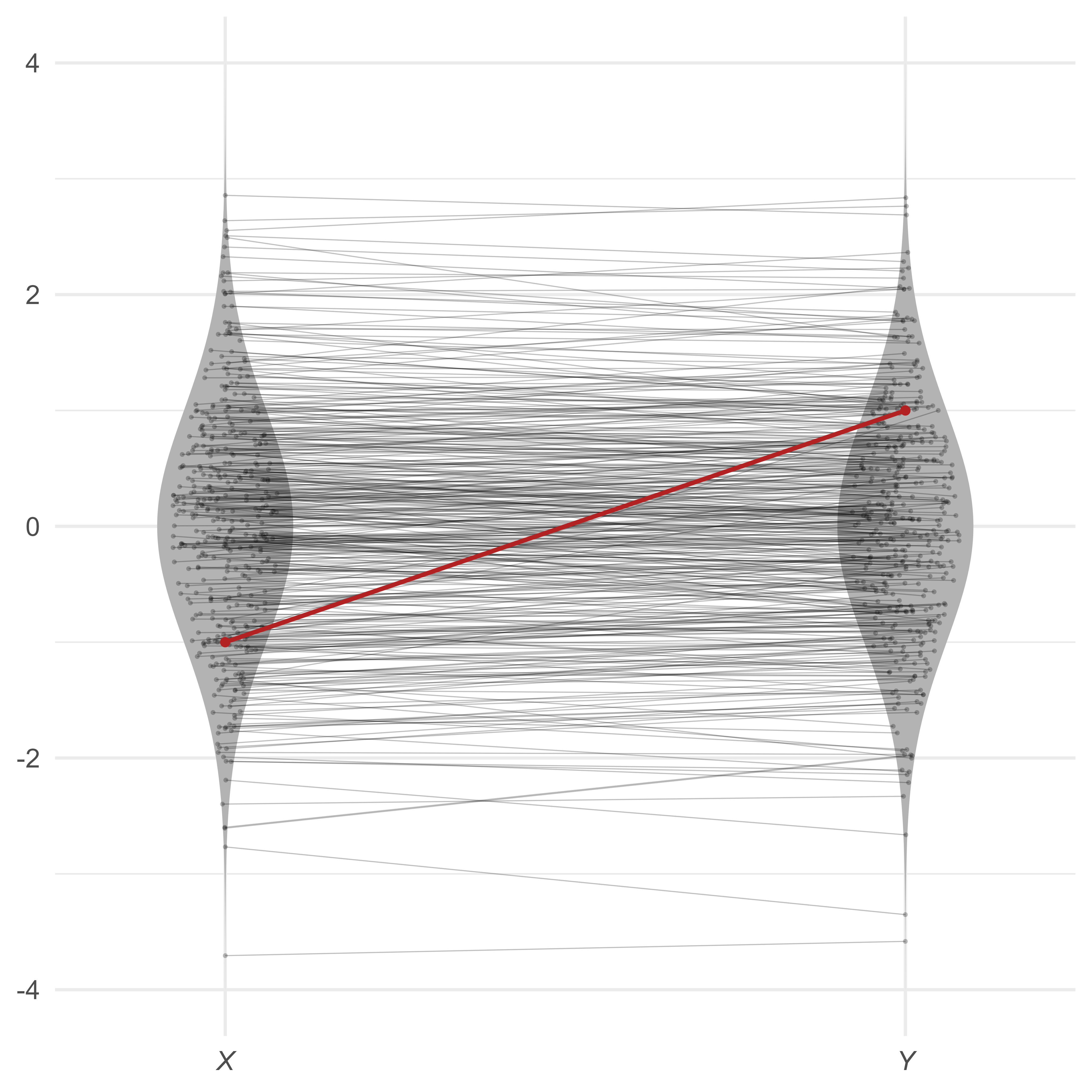
Scatterplots are great for inspecting multivariate outliers with a small number of variables. Unfortunately, scatterplots can only display 2 or 3 variables at a time. A different way to view multivariate data is to show each case as a profile of scores connected by lines. In Figure 3, most of the lines are nearly flat—highly correlated variables with the same means and standard deviations will generally produce flat profiles. The multivariate outlier, in red, is clearly not flat.
Suppose that we have four variables, all standard normal. Because the four variables correlate at 0.99, the profiles are all quite flat. However, the red profile {1,1,−1,1} is much less flat, making it unusual in this context.
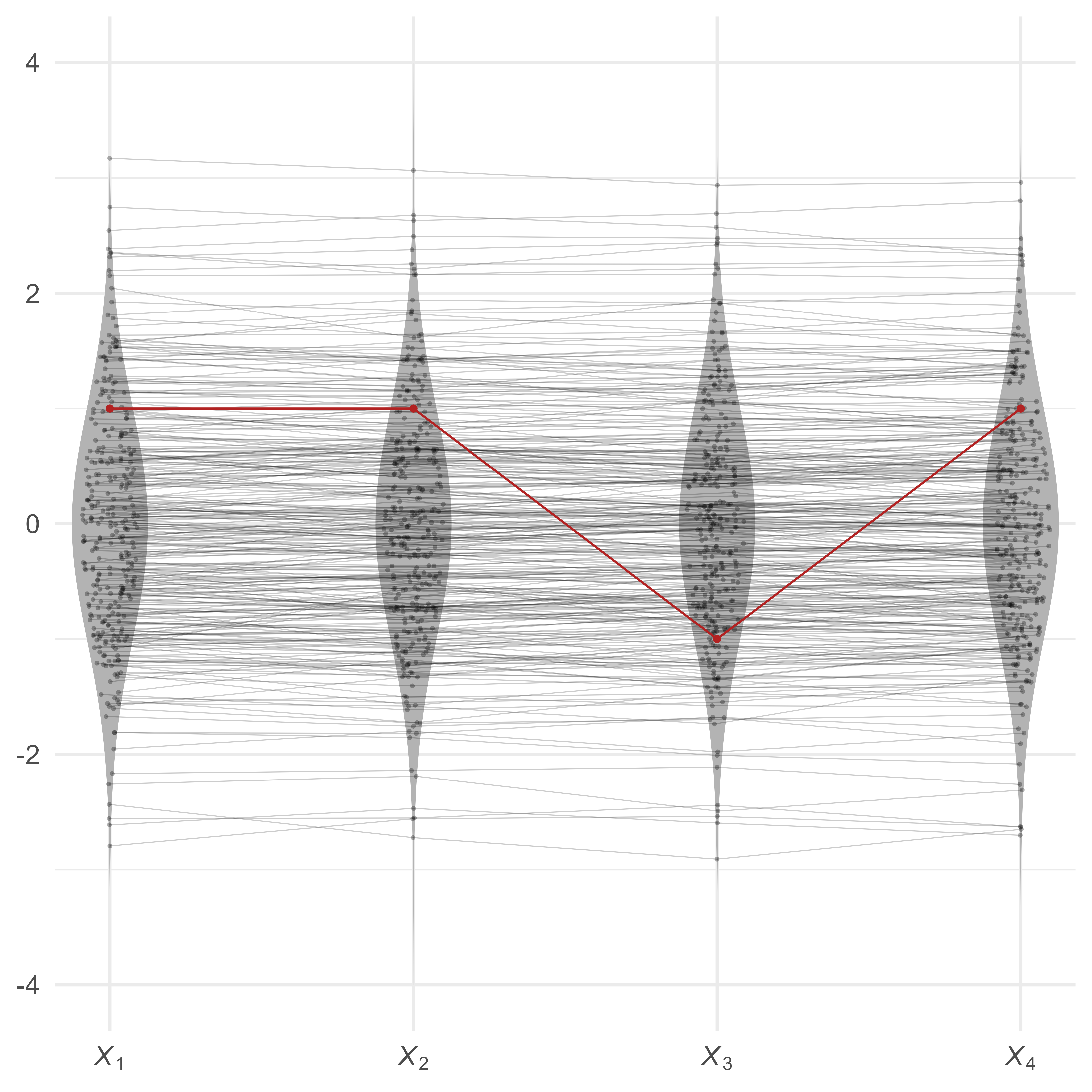
In Figure 4, the red profile is obviously unusual. However, we cannot yet tell exactly how unusual it is. We would like a measure of its multivariate extremity.
Quantifying Multivariate Extremity
The Euclidean Distance
The simplest (but ultimately unsatisfying) way to measure a profile’s multivariate extremity is with the Euclidean distance. A multidimensional extension of the Pythagorean Theorem, the Euclidean distance is the square root of the sum of the squared differences on each dimension from some reference point. The reference point of interest is usually the vector of means from each variable—the centroid. The Euclidean distance of point p1 = (1,1,−1,1) to the centroid p2 = (0,0,0,0) is
The Euclidean distance of point (1,1,1,1) to the centroid is also 2, yet if the two variables are highly correlated, point (1,1,−1,1) is much more unusual than point (1,1,1,1). Though fairly simple to calculate, the Euclidean distance is insensitive to the relationships among the variables, making it a poor choice for quantifying the extremity of profiles of correlated variables.
The Mahalanobis Distance
In 1936, P. R. Mahalanobis introduced a variant of the Euclidean distance that accounts for the covariance of the variables. Conceptually, the Mahalanobis distance is a Euclidean distance of profile scores if the variables are rotated and rescaled to fit on their principal component axes. Because principal components are always uncorrelated, distances in principal component space always have the same meaning regardless of the relationships of the original variables.
Computationally, the principal components need not be calculated explicitly. We simply need to invert the covariance matrix of the profile variables:
Where
is the Mahalanobis distance
is a vector of variable scores
is the vector of variable means of (i.e., the centroid of )
is the covariance matrix of the variables in vector
If the variables in X are normally distributed, essentially the Mahalanobis distance is creating principal component scores that are uncorrelated standard normal variates, squaring each score, and then summing each row of scores. Adding squared uncorrelated standard normal variates just so happens to be how the χ2 distribution is made. The degrees of freedom in the χ2 distribution corresponds to the number of standard normal variates that are squared and summed.
Thus, if there are k normally distributed variables in vector X, the Mahalanobis distance squared for vector X has a χ2 distribution with k degrees of freedom. In mathematical notation:
Thus, if we can assume the profile variables are multivariate normal, we can use the cumulative distribution function of the χ2 distribution to quantify how unusual a particular profile compares to the general population of profiles.
Suppose that a Mahalanobis distance for a row of data from 5 standard normal variates is 15.5. The cumulative distribution function for the χ2 distribution with 5 degrees of freedom is 0.992. Thus, the row of data is a multivariate outlier.
Conditional Mahalanobis Distances
A disadvantage of the Mahalanobis Distance is that it treats all the principal component dimensions equivalently. For highly correlated variables, the first principal component (or general factor) is of particular importance. We might want to distinguish between cases that are unusual on the first principal component and scores that are unusual on the remaining principal components.
For example, in a distribution of 4 highly correlated standardized variables, the point (4,4,4,4) is unusual because each point is unusual—four standard deviations above the mean. However, after accounting for its extreme elevation, the profile is perfectly flat. That is, the profile is unusually elevated, but has the modal profile shape. Of course, a perfectly flat profile is unusual in a different sense. It is extremely flat in the same sense that a score equal to the mean is extremely average.
In contrast, the point (−4, 4, −4, 4) is perfectly average in its elevation—the scores average to 0. It has, however, an unusually uneven shape.
Distinguishing Profile Shape from Profile Elevation
One way to define the profile elevation is to create a composite score from the sum of profile variables. All profiles that produce the same composite score are defined to have the same profile elevation. For ease of computation, the profile variables and the composite score can be re-scaled to have the same metric—preferably the z-score metric.
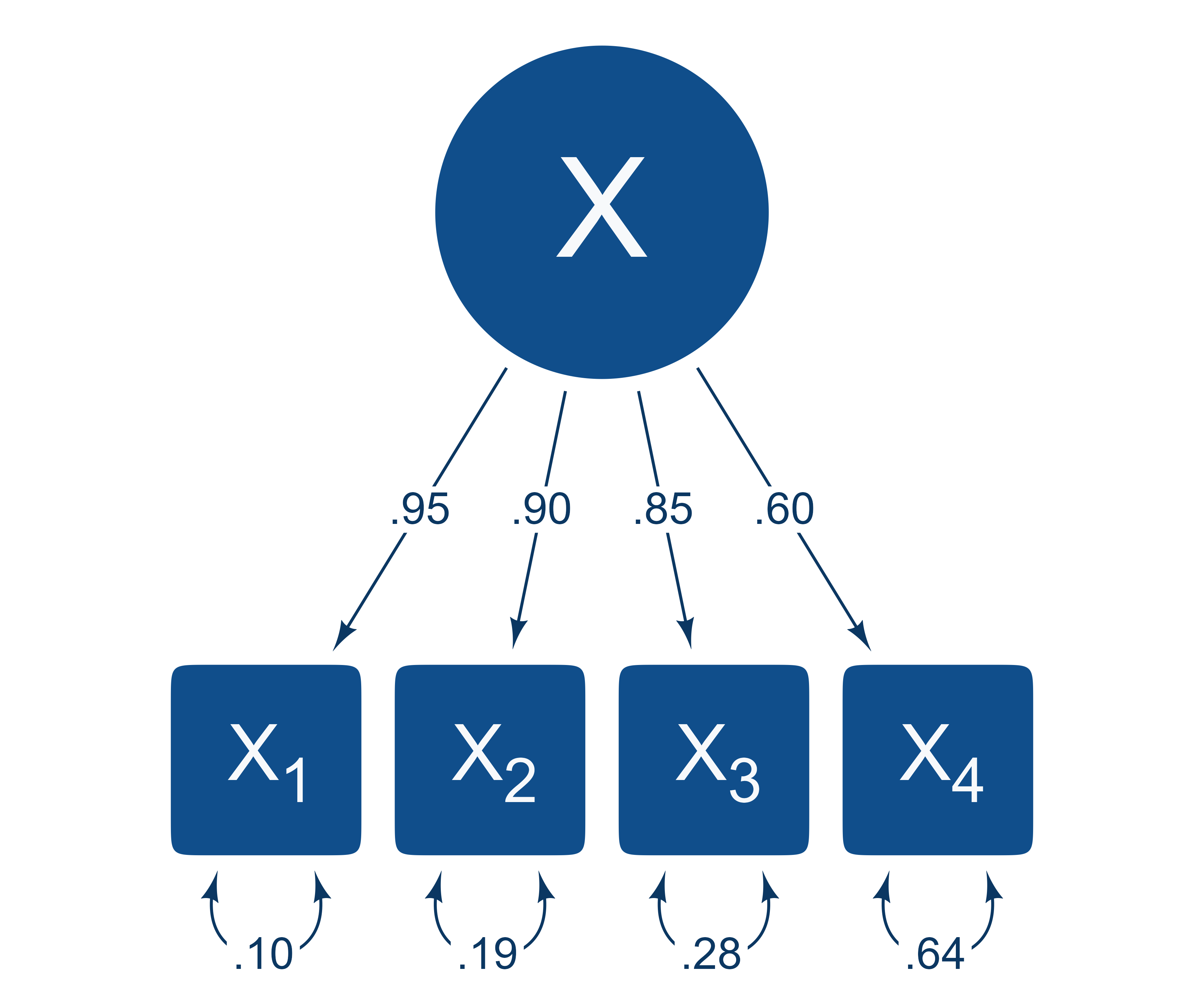
Suppose that we compare all profiles that have the same elevation but have different profile shapes. Imagine that four standardized variables correlate according to the structural model in Figure 5.
| X1 | X2 | X3 | X4 | |
|---|---|---|---|---|
| X1 | 1 | .86 | .81 | .57 |
| X2 | .86 | 1 | .76 | .54 |
| X3 | .81 | .76 | 1 | .51 |
| X4 | .57 | .54 | .51 | 1 |
The correlations among the four variables are in Table 1. Suppose from the population of profiles we select a subset of cases in which the profiles have an elevation of 1 (i.e., their composite score has a z-score of 1).
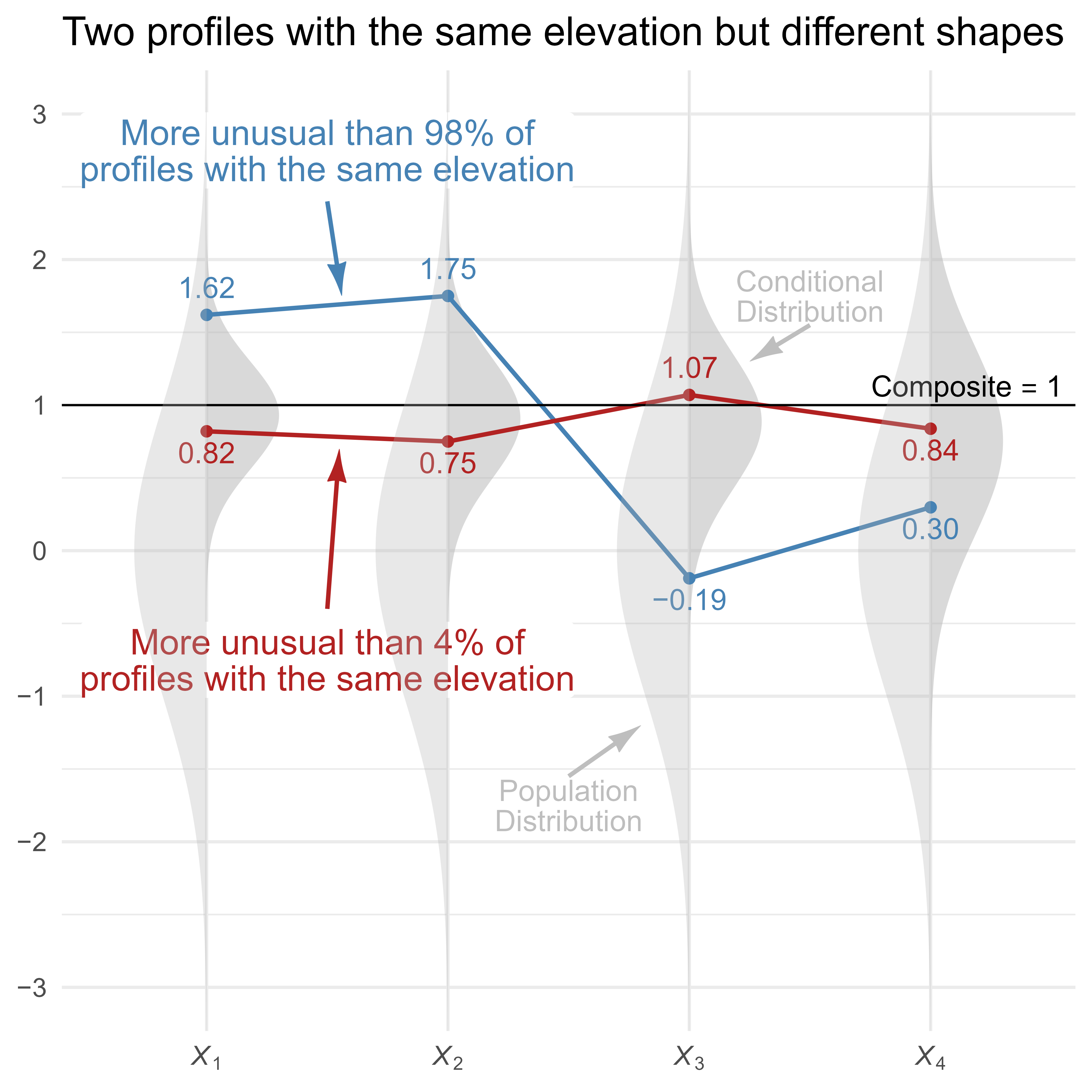
In Figure 6, two score profiles with an elevation of 1 are shown. The red profile is flat and unremarkable, whereas the blue profile is unusually uneven. The light gray vertical normal distribution on the left of each variable shows the population distribution of the unselected profiles, and the darker gray normal distribution on the right shows the conditional distributions of the selected profiles (i.e., all profiles with an elevation of 1). Note that X1 has a relatively narrow conditional distribution because its loading of λ = 0.95 is high, and X4 has a relatively wide conditional distribution because its loading of λ = 0.6 is lower.
A Worked Example with a Simple Model
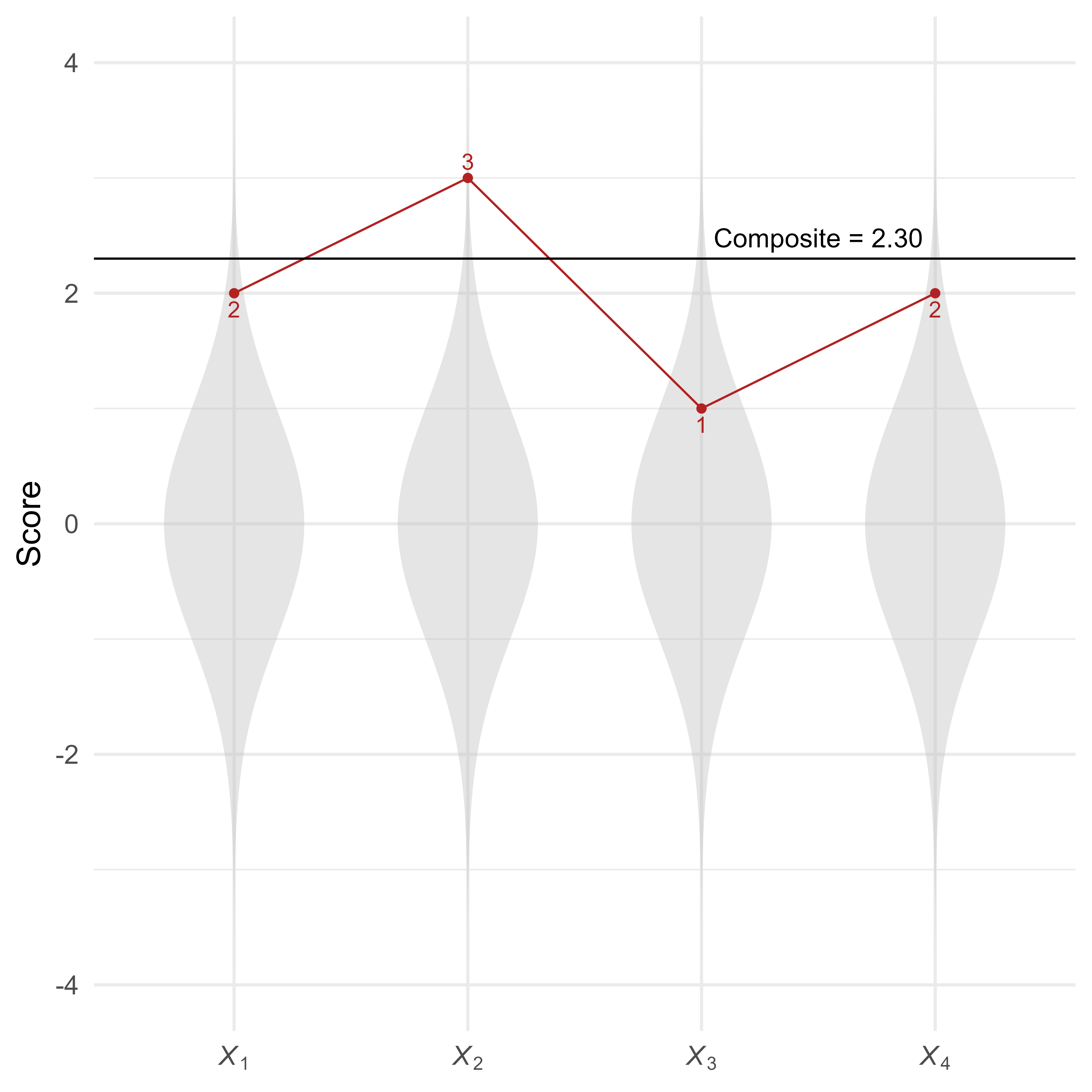
Suppose that among standard multivariate normal variables, there is a profile of scores :
As seen in Figure 7, this profile of scores is summarized by a composite score of 2.30.
How can we calculate the Mahalanobis distance for profiles that all have the same elevation (i.e., composite score)? We will show how to do so in two ways. The easier of the two methods will be to use the simstandard package to create the data and the unusualprofile package to calculate the conditional Mahalanobis distance. For your reference, we also see how to do everything “by hand” using matrix algebra in the Calculations performed by the unusualprofile package vignette.
Calculations Using the simstandard and unusualprofile Packages
First we load several packages.
The simstandard package can create simulated multivariate normal data from a structural equation model. The first step is to specify the model using lavaan syntax:
model <- "X =~ 0.95 * X_1 +
0.90 * X_2 +
0.85 * X_3 +
0.60 * X_4"Using the simstandard package, we can find the model-implied correlation matrix.
# Model-implied correlations of all variables
R_all <- simstandard::get_model_implied_correlations(model, composites = TRUE)
R_all
#> X_1 X_2 X_3 X_4 X_Composite
#> X_1 1.0000000 0.8550000 0.8075000 0.5700000 0.9294705
#> X_2 0.8550000 1.0000000 0.7650000 0.5400000 0.9086239
#> X_3 0.8075000 0.7650000 1.0000000 0.5100000 0.8863396
#> X_4 0.5700000 0.5400000 0.5100000 1.0000000 0.7533527
#> X_Composite 0.9294705 0.9086239 0.8863396 0.7533527 1.0000000Using the same model, we can calculate composite scores from profile data like so:
# Create data.frame, and add the composite score
d <- data.frame(
X_1 = 2,
X_2 = 3,
X_3 = 1,
X_4 = 2
) %>%
simstandard::add_composite_scores(m = model)This will result in a single row of data, with observed test scores and a composite variable:
d
#> X_1 X_2 X_3 X_4 X_Composite
#> 1 2 3 1 2 2.300314Although we can enter the names of the variables into the cond_maha function by hand, with large models it is less tedious to do so programmatically. Here we select the independent variable X_Composite:
Here we select the dependent variables:
Now we use the cond_maha function to calculate the conditional Mahalanobis distance. Because the “independent” composite score can be predicted perfectly from the dependent scores, we specify it using the v_ind_composite parameter. Had it simply had been a predictor of the variables, it would have been specified using the v_ind parameter.
# Calculate the conditional Mahalanobis distance
cm <- cond_maha(
data = d,
R = R_all,
v_dep = v_X,
v_ind_composites = v_X_composite
)
cm
#> Conditional Mahalanobis Distance = 2.9246, df = 3, p = 0.9641The output of the cond_maha function can be displayed with the plot function.
plot(cm)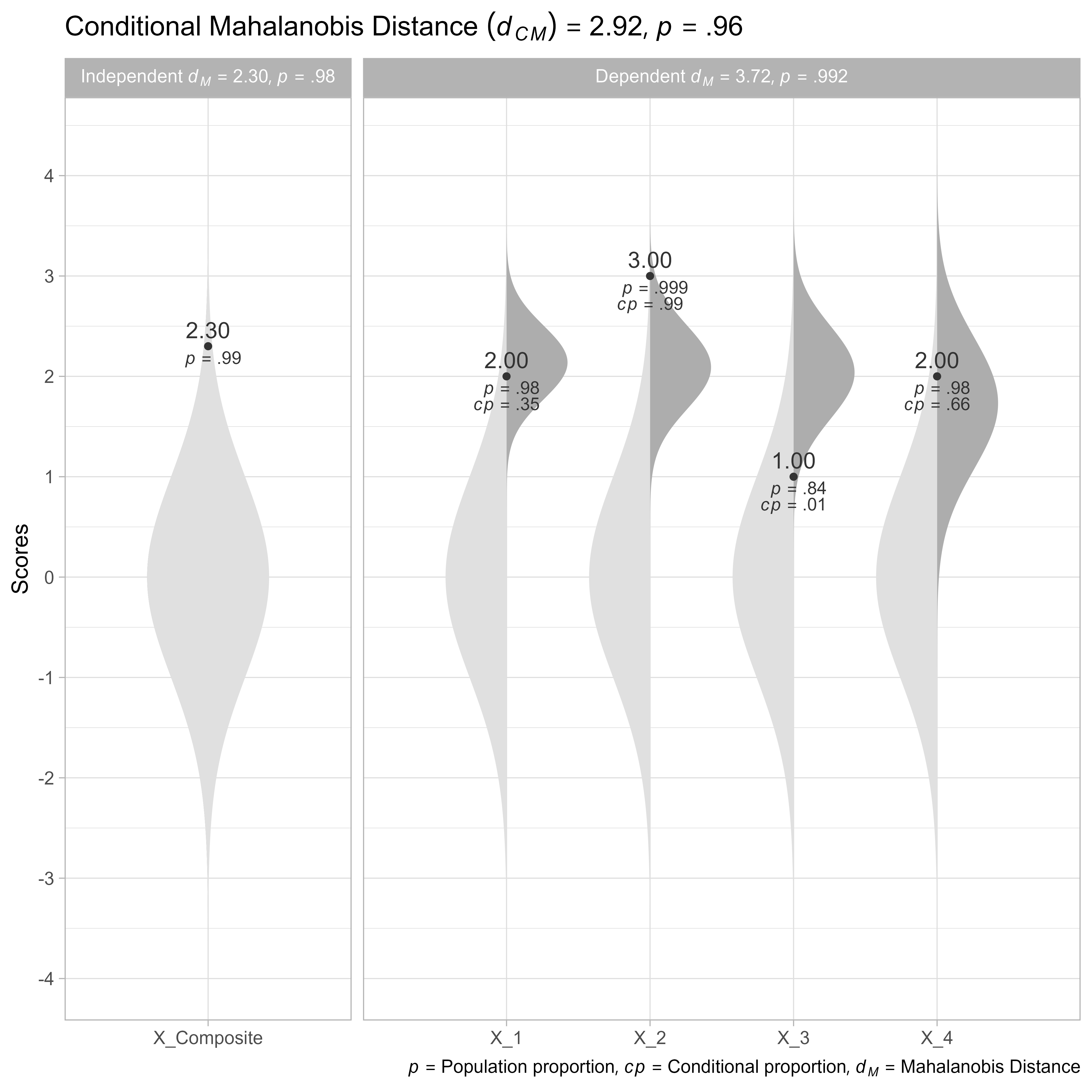
In Figure 8, we can see that the profile is more unusual than 96.41% of profiles with the same elevation (i.e., a composite score of z = 2.3). The conditional Mahalanobis distance of the dependent variables is 2.92, which is a 21% smaller than the unconditional Mahalanobis distance of the dependent variables 3.72.
Note that the Mahalanobis distance of the independent variable is 2.3. When added, the squared conditional Mahalanobis distance and the squared Mahalanobis distance of the independent variable equal the squared unconditional unconditional Mahalanobis distance of the dependent variables (within rounding error).
It is not a coincidence that this relationship resembles the Pythagorean theorem. In principal component space, these distances form a right triangle. However, this equation only holds true when the independent variables are perfectly predicted by the dependent variables such as when the independent variables are composites of the dependent variables.
View Complete Output of cond_maha Function
By default, the cond_maha function prints just the the most important information.
If you would like to see everything in the output of the cond_maha function, you can use the View or str function to see the entire list.
A Worked Example with a More Complex Model
d_case <- tibble(
Ga1 = 61,
Ga2 = 65,
Ga3 = 69,
Gc1 = 109,
Gc2 = 97,
Gc3 = 103,
RD1 = 77,
RD2 = 71,
RD3 = 81,
RC1 = 90,
RC2 = 94,
RC3 = 99
) %>%
simstandard::add_factor_scores(m = m_reading,
mu = 100,
sigma = 15,
CI = TRUE) %>%
simstandard::add_composite_scores(m = m_reading, mu = 100, sigma = 15)
d_LB <-
select(d_case, ends_with("_LB")) %>%
rename_with(~str_remove(., "_FS")) %>%
pivot_longer(cols = everything())
d_UB <-
select(d_case, ends_with("_UB")) %>%
rename_with(~str_remove(., "_FS")) %>%
pivot_longer(cols = everything())
d_FS <-
select(d_case, ends_with("_FS")) %>%
pivot_longer(cols = everything())
bind_rows(d_LB,
d_UB,
d_FS) %>%
separate(name, c("Ability", "Role")) %>%
pivot_wider(names_from = Role, values_from = value) %>%
ggplot(aes(Ability, FS)) +
geom_point() +
geom_errorbar(aes(ymin = LB, ymax = UB), width = 0.1)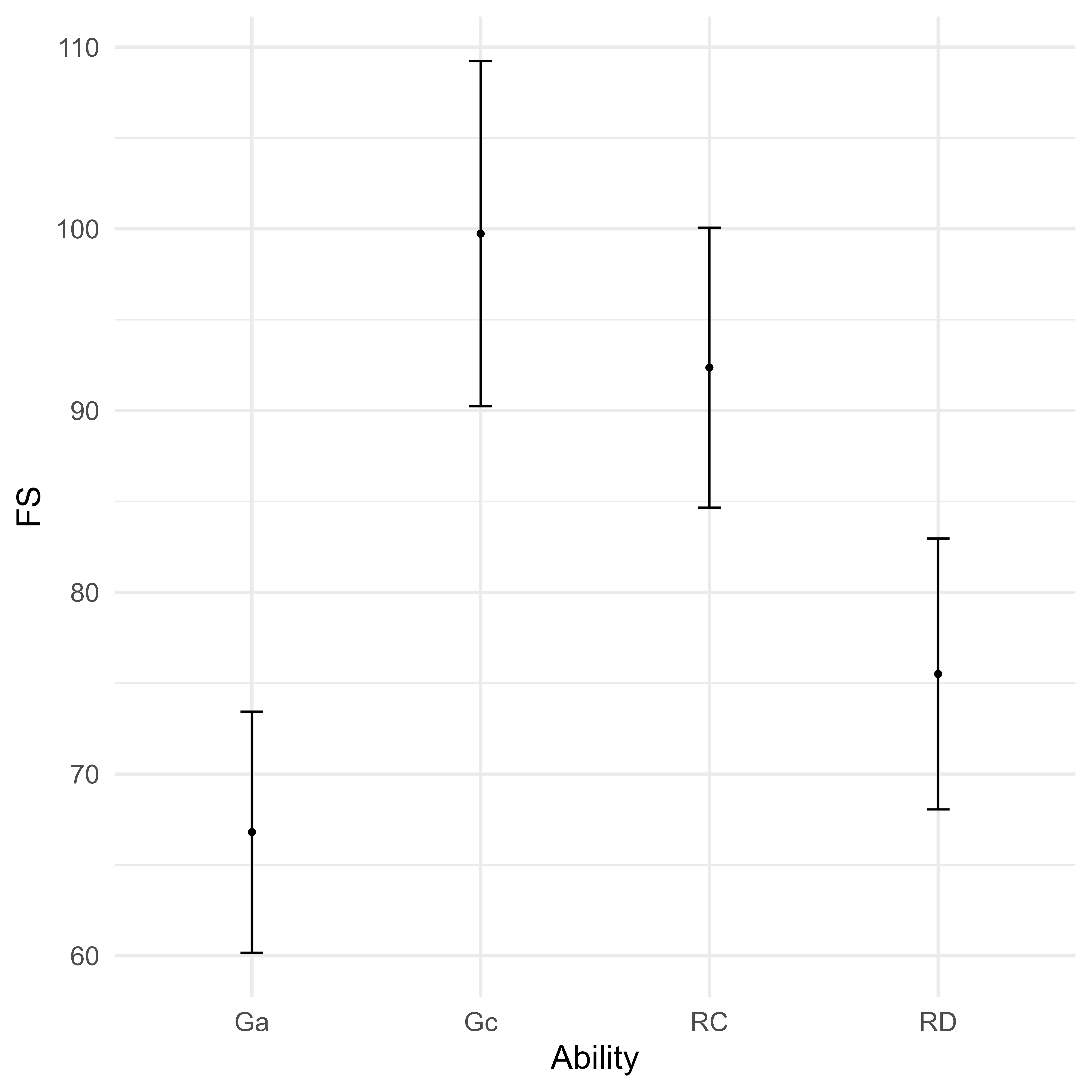

Suppose we have a simplified model of reading ability and its predictors as shown in Figure 10. The two predictors of reading ability are General Comprehension/Knowledge (Gc) and General Auditory Processing (Ga). These cognitive abilities are precursor abilities to Reading Decoding (RD) and Reading Comprehension (RC). Ga is a stronger predictor of RD than of RC. For Gc, the reverse is true. Each cognitive and academic ability is measured with three tests each.
We want to know if a person’s pattern of reading scores are unusual, given the cognitive scores.
Here we load packages we will need.
We can use lavaan syntax to specify the standardized coefficients of our model.
# Model of Reading
m_reading <- "
Ga =~ 0.83 * Ga1 + 0.92 * Ga2 + 0.95 * Ga3
Gc =~ 0.88 * Gc1 + 0.71 * Gc2 + 0.85 * Gc3
RD =~ 0.93 * RD1 + 0.87 * RD2 + 0.85 * RD3
RC =~ 0.91 * RC1 + 0.86 * RC2 + 0.90 * RC3
Ga ~~ 0.68 * Gc
RD ~ 0.57 * Ga + 0.33 * Gc
RC ~ 0.05 * Ga + 0.40 * Gc + 0.43 * RD
"Here we enter the standard scores (Mean = 100, SD = 15) for a single person. Then we convert each standard score to z-scores. Finally, we use the simstandard package’s add_composite_scores and add_factor_scores function to add composite scores and estimated factor scores to the data frame.
d_case <- tibble(
Ga1 = 61,
Ga2 = 65,
Ga3 = 69,
Gc1 = 109,
Gc2 = 97,
Gc3 = 103,
RD1 = 77,
RD2 = 71,
RD3 = 81,
RC1 = 90,
RC2 = 94,
RC3 = 99
) %>%
simstandard::add_composite_scores(m = m_reading, mu = 100, sigma = 15) %>%
simstandard::add_factor_scores(m = m_reading, mu = 100, sigma = 15)| Ability | Score | z-score | p |
|---|---|---|---|
| Ga (Composite) | 62.53 | -2.50 | .0062 |
| Ga (Factor Score) | 66.80 | -2.21 | .01 |
| Ga1 | 61.00 | -2.60 | .0047 |
| Ga2 | 65.00 | -2.33 | .01 |
| Ga3 | 69.00 | -2.07 | .02 |
| Gc (Composite) | 103.41 | 0.23 | .59 |
| Gc (Factor Score) | 99.73 | -0.02 | .49 |
| Gc1 | 109.00 | 0.60 | .73 |
| Gc2 | 97.00 | -0.20 | .42 |
| Gc3 | 103.00 | 0.20 | .58 |
| RC (Composite) | 93.89 | -0.41 | .34 |
| RC (Factor Score) | 92.36 | -0.51 | .31 |
| RC1 | 90.00 | -0.67 | .25 |
| RC2 | 94.00 | -0.40 | .34 |
| RC3 | 99.00 | -0.07 | .47 |
| RD (Composite) | 74.38 | -1.71 | .04 |
| RD (Factor Score) | 75.51 | -1.63 | .05 |
| RD1 | 77.00 | -1.53 | .06 |
| RD2 | 71.00 | -1.93 | .03 |
| RD3 | 81.00 | -1.27 | .10 |
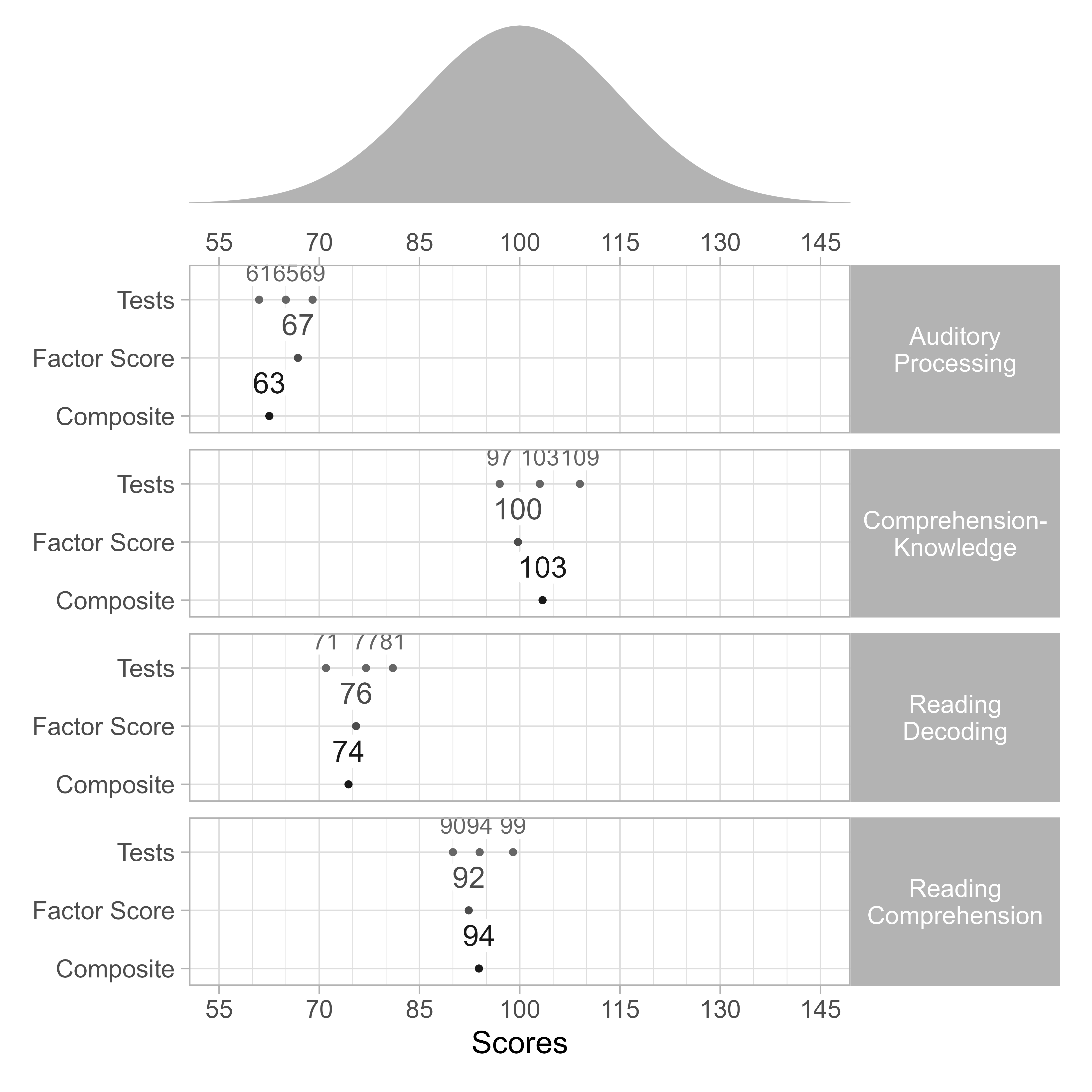
Conditional Mahalanobis Distances with Indicator Scores Only
Suppose that we want to know if the academic performance scores are unusual, given the cognitive predictor scores.
The variable names for the cognitive predictors and the reading ability scores can be specified like so:
Now let’s see if the academic scores are unusual after controlling for the cognitive predictors:
dCM <- cond_maha(
data = d_case,
R = simstandard::get_model_implied_correlations(m_reading),
mu = 100,
sigma = 15,
v_dep = v_reading,
v_ind = v_cognitive)Controlling for the cognitive predictors, did not alter our conclusion that the reading profile is unusual. It appears that the Reading scores are more unusual than about 18% of Reading profiles from people with the same specified cognitive predictor scores.
We can see that all three decoding tests are lower than expectations, particularly RD2, the reading comprehension tests are within expectations, though RC3 is somewhat high.
plot(dCM)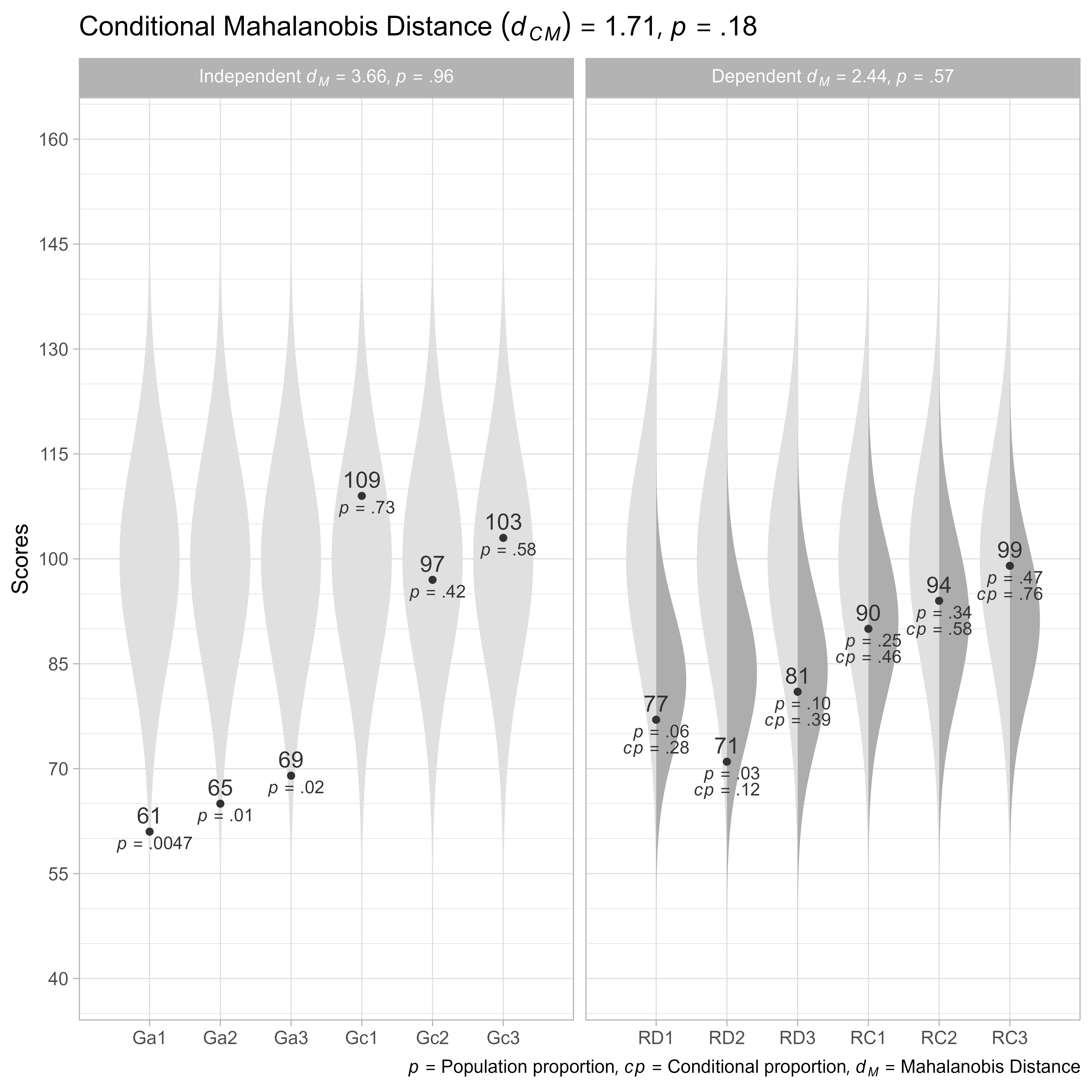
Composite Score Model
Often, all we need do is calculate the composite scores and see if they are within expectations.
First, we specify the composite score variable names to be the same as they are in the d_case tibble.
Now we plot the composite scores:
# Conditional Reading Profile
cond_maha(data = d_case,
R = get_model_implied_correlations(m_reading, composites = TRUE),
v_dep = v_reading_composite,
v_ind = v_cognitive_composite,
mu = 100,
sigma = 15) %>%
plot()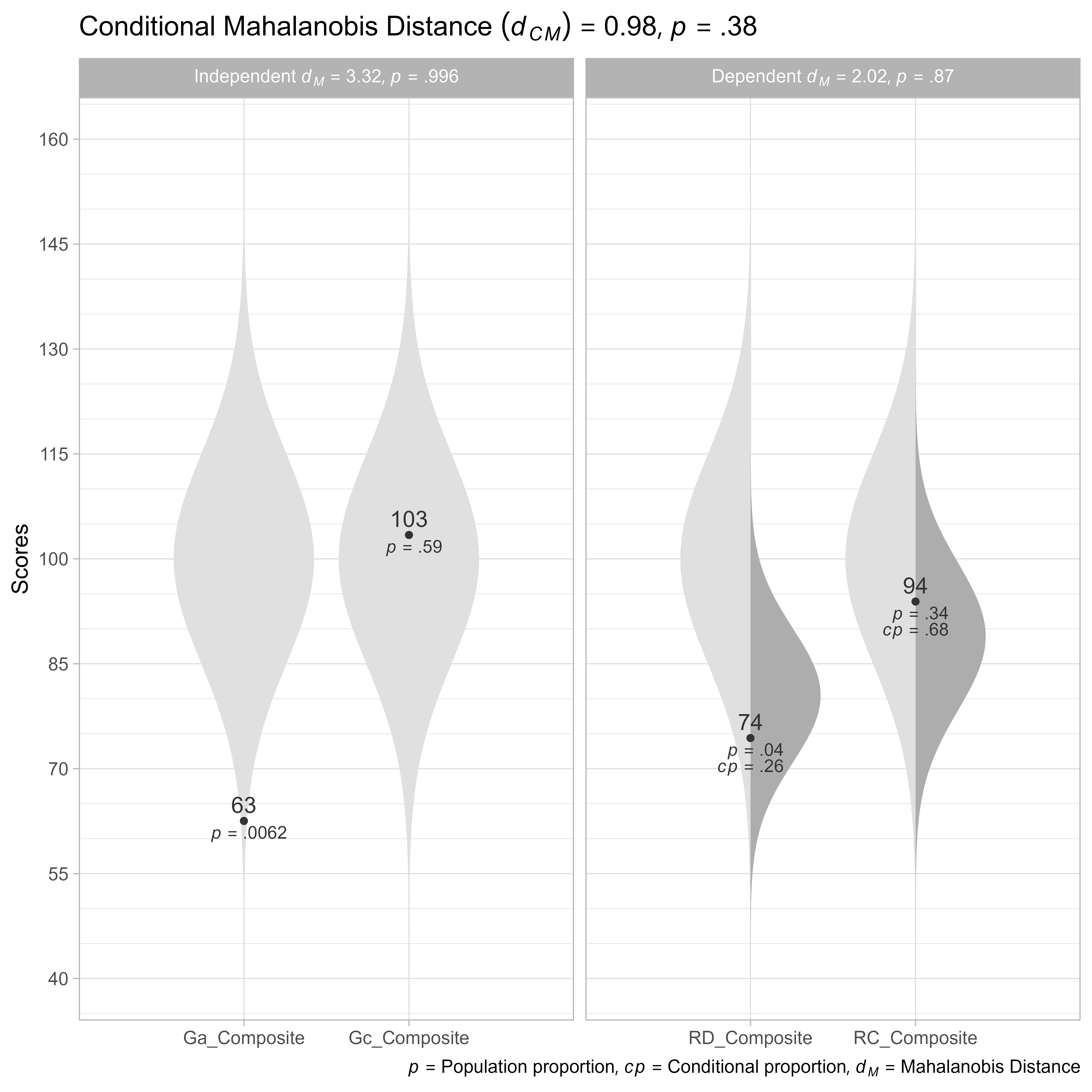
Observed Scores, Given Composite Scores
Suppose that we want to know if the observed Gc scores are unusual, given the composite Gc score we have estimated.
cond_maha(
d_case,
R = get_model_implied_correlations(m_reading, composites = TRUE),
v_dep = c(v_cognitive, v_reading),
v_ind = c(v_cognitive_composite, v_reading_composite),
mu = 100,
sigma = 15
) %>%
plot() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))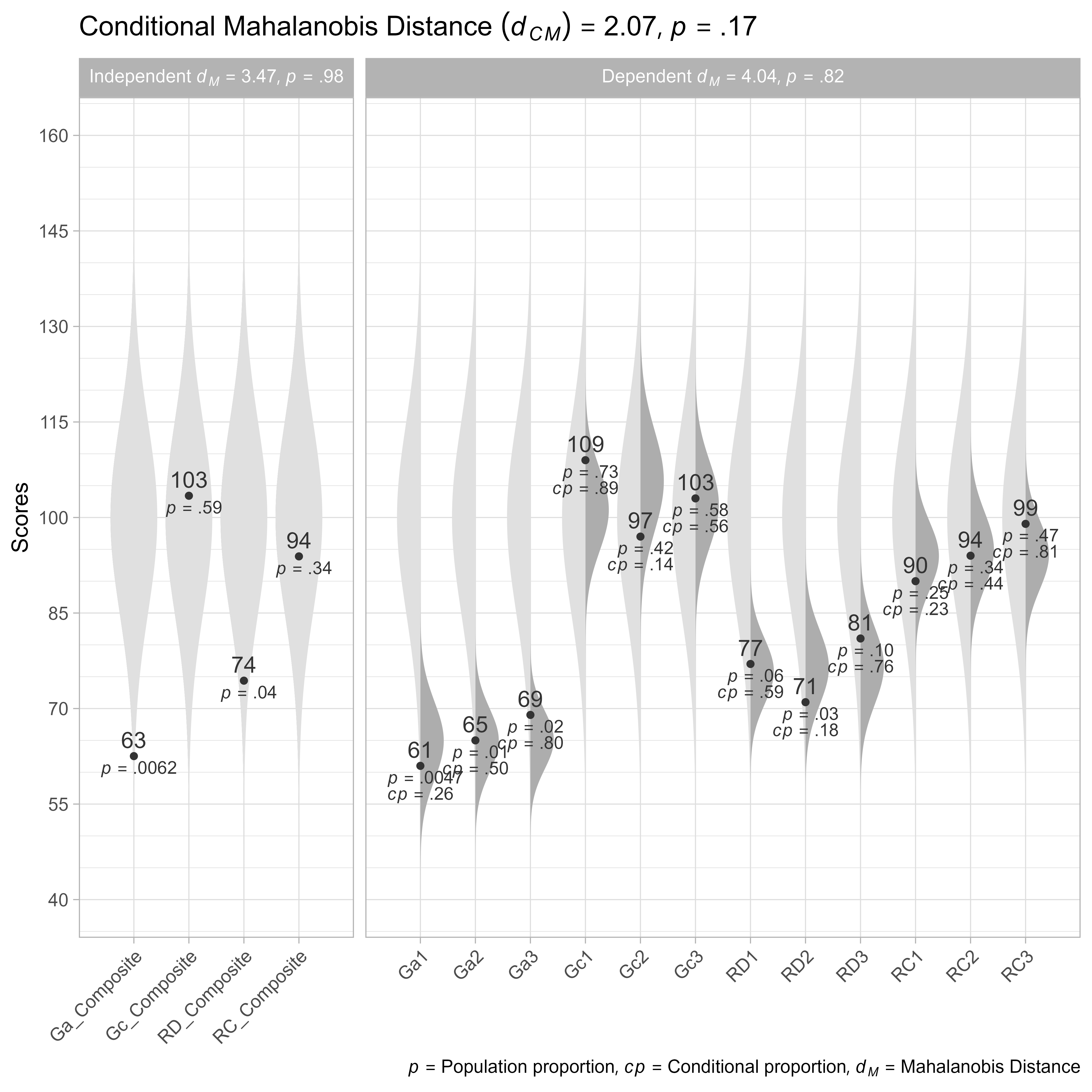
Factor-score model
Factor scores can be calculated calculated using Thurstone’s method (Thurstone, 1935):
Where
is a vector of a person’s estimated factor scores.
is the correlation matrix among the latent factors.
is the matrix of loadings from factors to observed scores.
is a correlation matrix between the common factors and the observed variables.
is the inverse of the correlation matrix among the observed variables.
is a vector of a person’s standardized scores on the observed variables.
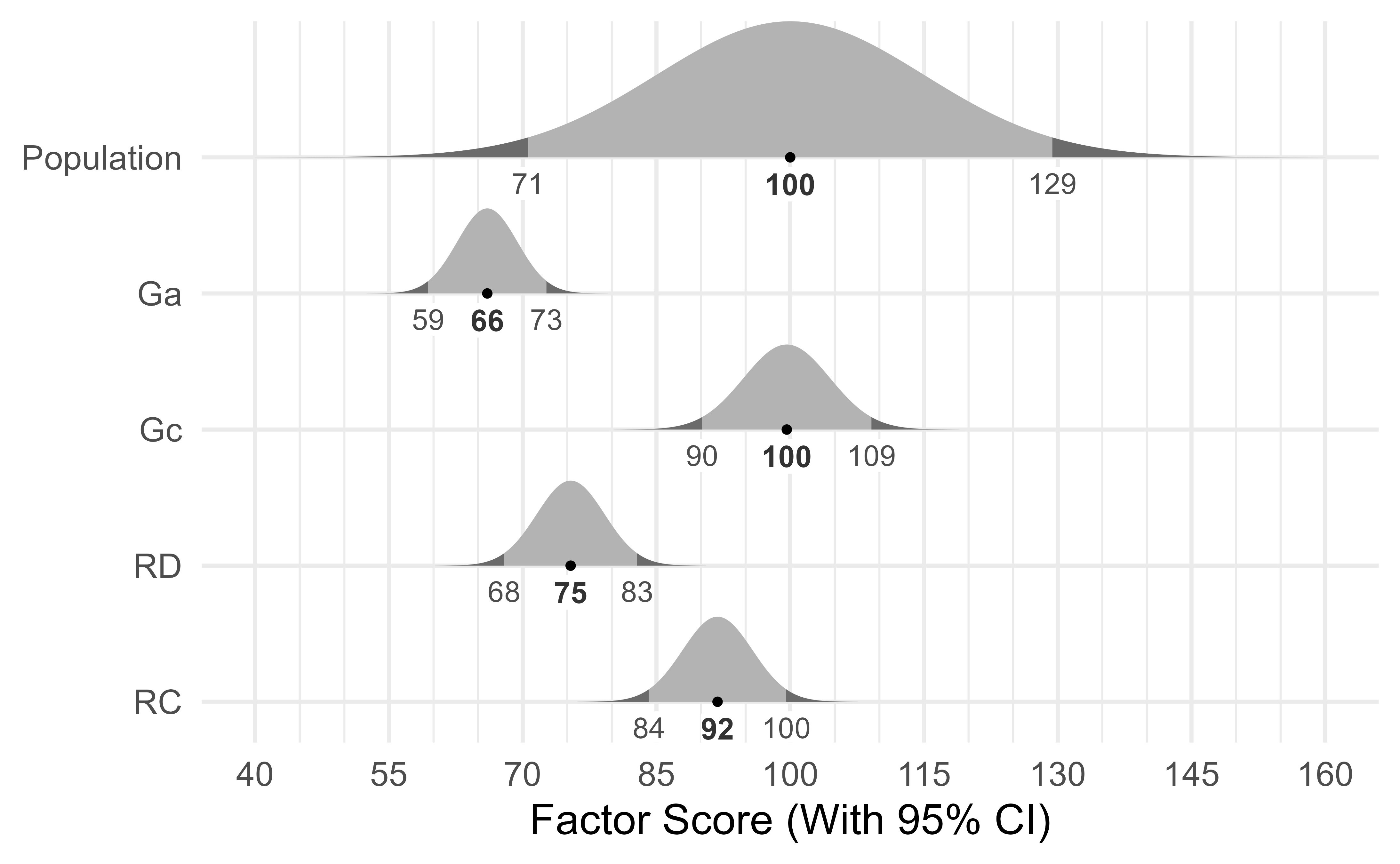
Fortunately, the add_factor_scores function from the simstandard package can add factor scores to existing data. For each latent variable in the model, a factor score with “_FS” is appended to the variable name. Using the option CI = TRUE will produce the lower bounds (“_FS_LB”) and upper bounds (“_FS_UB”) of the factor scores’ confidence intervals.
d_case <- tibble(
Ga1 = 61,
Ga2 = 69,
Ga3 = 65,
Gc1 = 109,
Gc2 = 97,
Gc3 = 103,
RD1 = 77,
RD2 = 71,
RD3 = 81,
RC1 = 90,
RC2 = 99,
RC3 = 94
) %>%
simstandard::add_factor_scores(m = m_reading,
mu = 100,
sigma = 15,
CI = TRUE)
d_case %>%
select(contains("_FS")) %>%
pivot_longer(everything(),
names_to = "Variable",
values_to = "Score") %>%
arrange(Variable)
#> # A tibble: 12 × 2
#> Variable Score
#> <chr> <dbl>
#> 1 Ga_FS 66.0
#> 2 Ga_FS_LB 59.4
#> 3 Ga_FS_UB 72.7
#> 4 Gc_FS 99.6
#> 5 Gc_FS_LB 90.1
#> 6 Gc_FS_UB 109.
#> 7 RC_FS 91.9
#> 8 RC_FS_LB 84.2
#> 9 RC_FS_UB 99.6
#> 10 RD_FS 75.4
#> 11 RD_FS_LB 67.9
#> 12 RD_FS_UB 82.8Because factor scores are estimates, they are presented with confidence intervals in Figure 15.
There are two ways we can think of factor scores. From one perspective, they are composite scores with each component given a different weight.
For example, to make factor scores for the reading model, one would use the factor-score coefficients presented in Figure 16. The matrix of factor-score coefficients can be obtained like so:
simstandard::get_factor_score_coefficients(m_reading)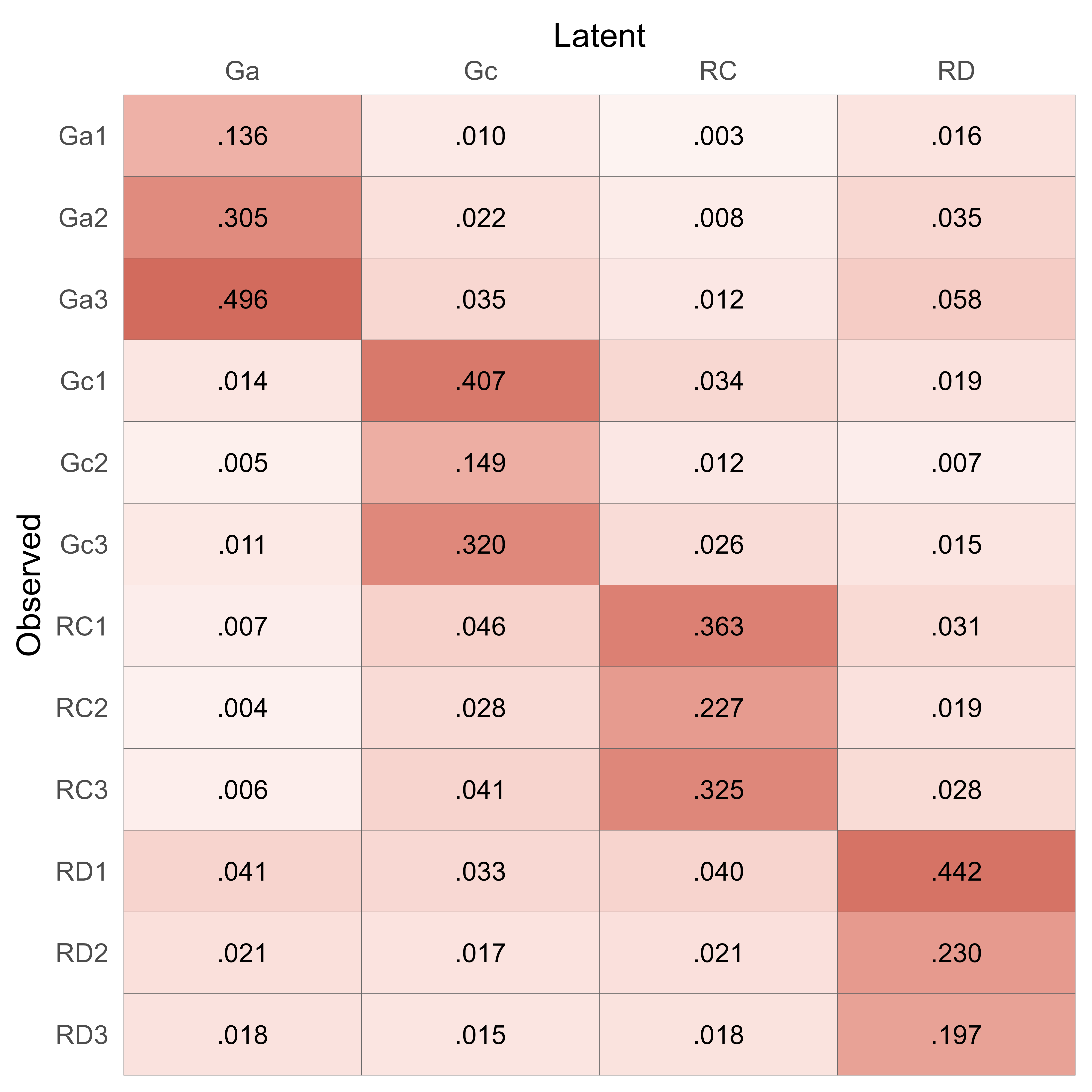
Factor scores generally have a smaller standard deviation than the latent scores they estimate. Instead, their standard deviation is proportional to their validity. If a factor score measures a latent score poorly, it strongly regresses to the mean, resulting in a much smaller variance than that of the latent variable.
# Correlation matrix
R_factor <- get_model_implied_correlations(m_reading,
factor_scores = TRUE)
# Factor Score Validity
fs_validity <- get_factor_score_validity(m_reading)
# Model names
m_names <- get_model_names(m_reading)
# Observed score names
ob_names <- m_names$v_observed
# Factor Score names
fs_names <- m_names$v_factor_score
# Standard Deviations
s <- 15 * c(rep(1, length(ob_names)), fs_validity)
names(s) <- c(ob_names, names(fs_validity))
# Plot
cond_maha(
d_case,
R = R_factor,
mu = 100,
sigma = s,
v_dep = ob_names,
v_ind_composites = fs_names
) %>%
plot()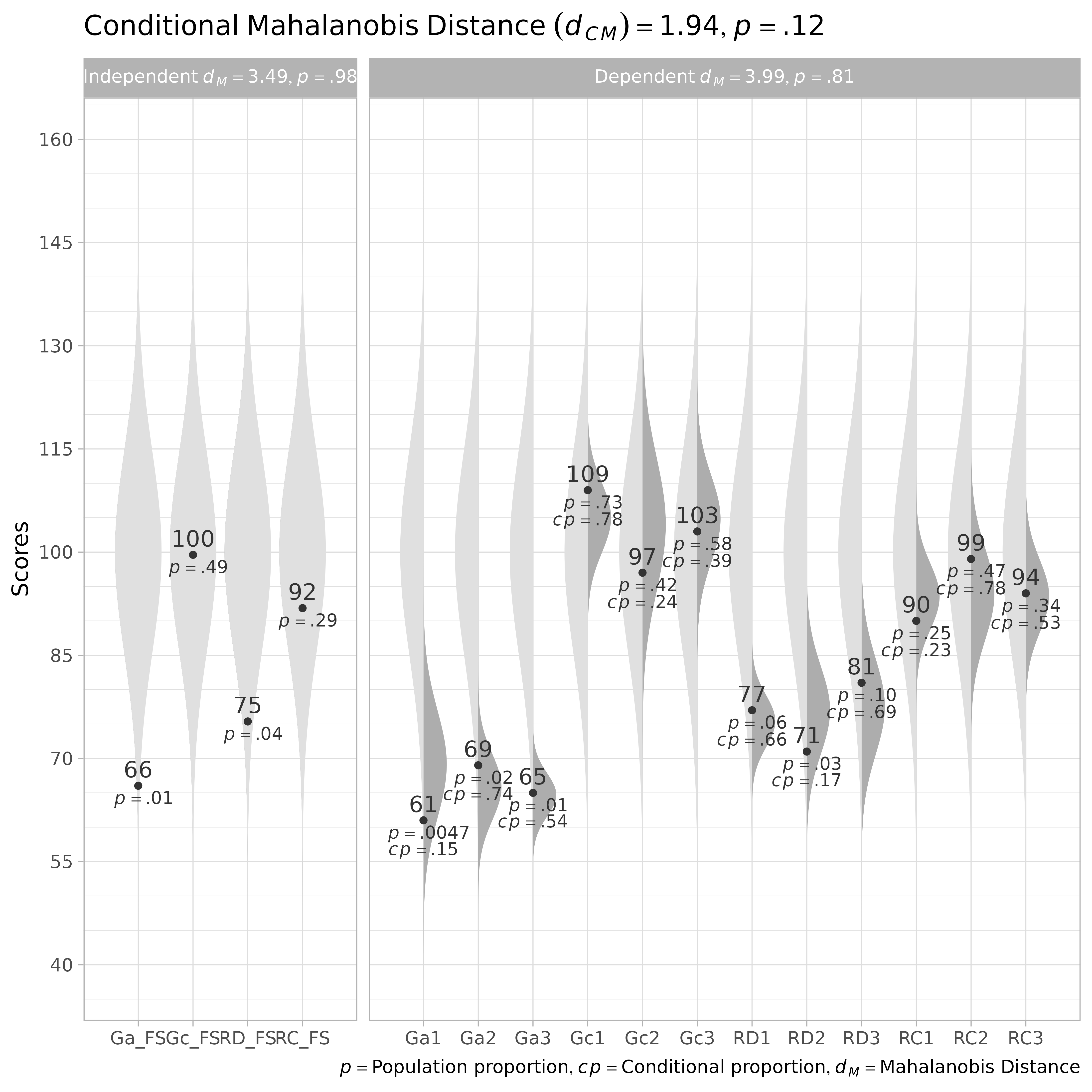
A second interpretation of the factor scores is that they are best estimates of a latent variable. Here, we get the model-implied correlation matrix of observed and latent variables (instead of factor score estimates).
# Get model-implied correlations of observed and latent variables
R_latent <- get_model_implied_correlations(m_reading, latent = TRUE)
# Latent variable names
v_latent <- m_names$v_latent
# Plot
d_case %>%
rename_with(.fn = ~ str_remove(.x, "_FS$")) %>%
cond_maha(
R = R_latent,
mu = 100,
sigma = 15,
v_dep = ob_names,
v_ind = v_latent
) %>%
plot()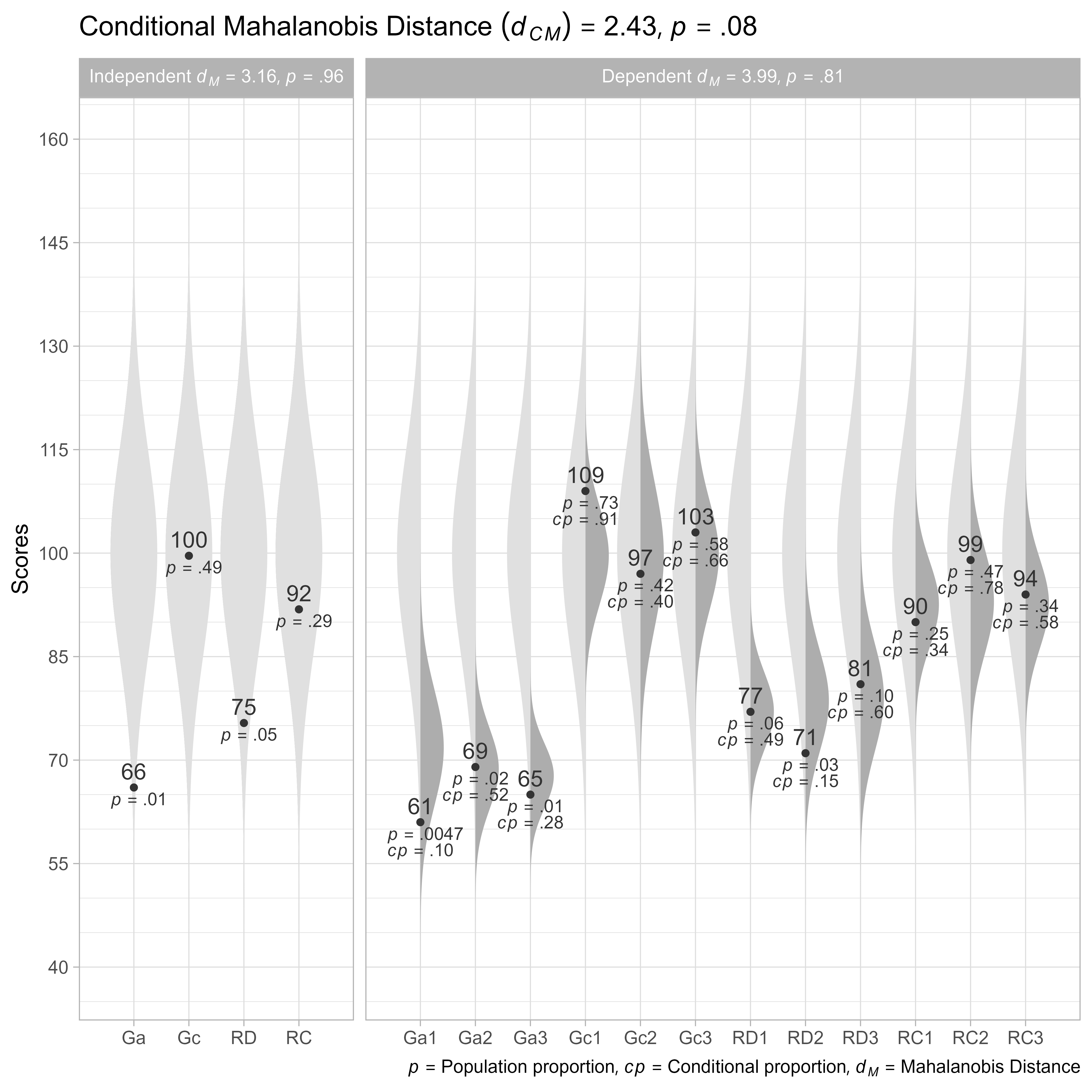
Note that we had to rename the factor score variables from Ga_FS, Gc_FS, RD_FS, RC_FS to Ga, Gc, RD, RC. In addition, the latent variables are no longer composite variables, but independent variables.